This document shows how you can do local development in .NET Core with Prometheus and Grafana for instrumentation. Using this document, you can run both Prometheus and Grafana locally (I use a MacBook Pro). In addition, you can deploy either or both tools in separate Docker containers.
Prometheus
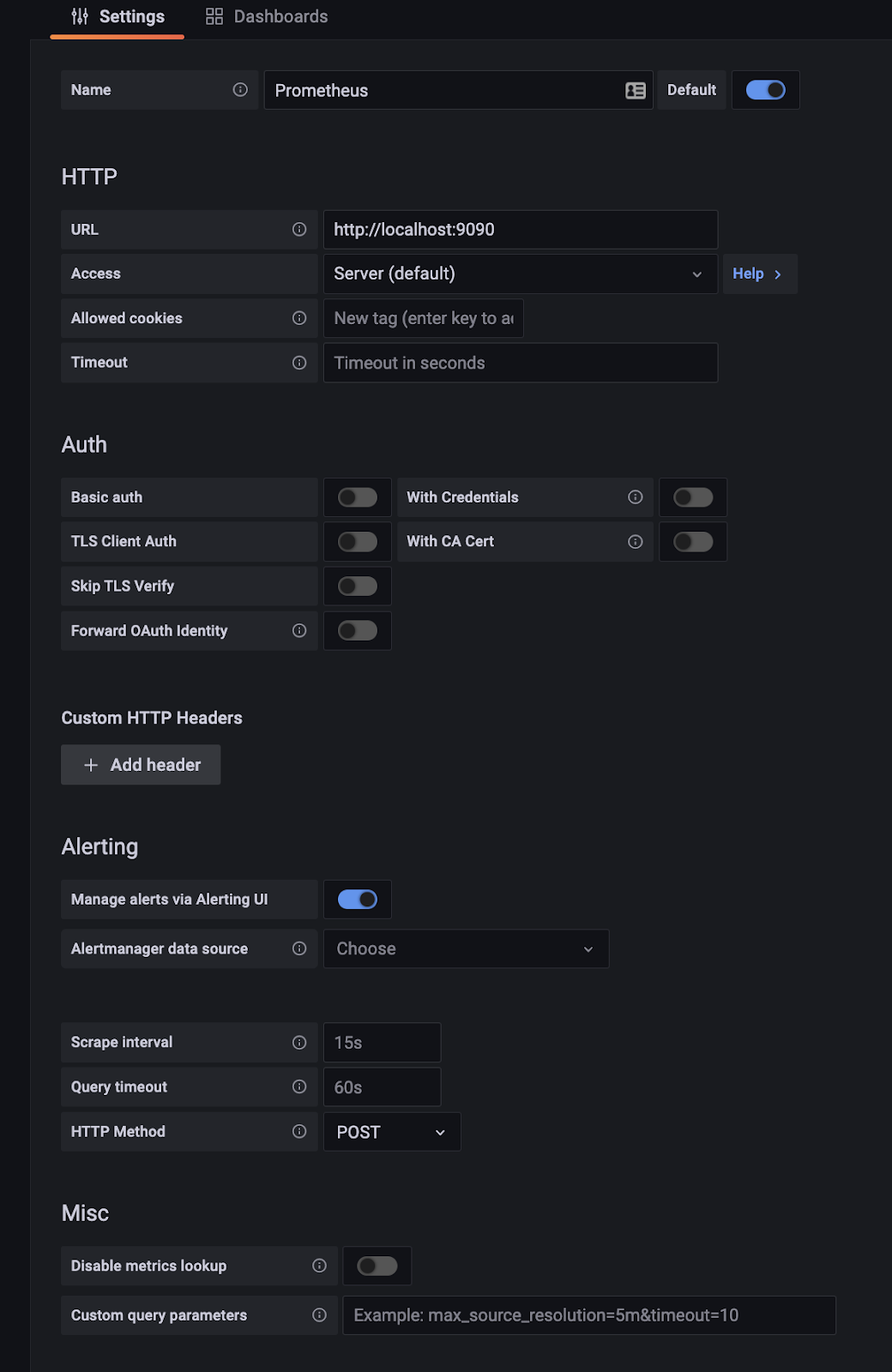
Download Prometheus. Extract the compressed TAR file and move the folder into another directory.
Change the prometheus.yml configuration file. At the bottom of the file is the scrape targets. Change the URL (and the port) to where the .NET application is going to be publishing its metrics. For example, if the .NET app is publishing to port 9934 using the KestrelMetricServer, then change the target to localhost:9934.
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. – job_name: “prometheus”
# metrics_path defaults to ‘/metrics’ # scheme defaults to ‘http’.
static_configs: – targets: [“localhost:9934”] <- Change it here
Start Prometheus by running the command:
./prometheus –config.file=”prometheus.yml”
Grafana
Download Grafana and extract the compressed TAR file and move the folder into another directory.
Go to the Grafana folder and run the command:
./bin/grafana-server web
The .NET Core Application
Let’s assume that we have a .NET Core application. We can initialize Prometheus using the first three statements below. Assume that the .NET application is outputting some custom counters on localhost:9934. We also have some helper functions that will output data to a Prometheus counter.
We use two NuGet packages: prometheus-net and prometheus-net.AspNetCore.
using Prometheus;
Metrics.SuppressDefaultMetrics(); this.MetricsServer = new KestrelMetricServer(host, port); this.MetricsServer.Start();
public void Counter(CounterMonitorData data) { var counter = this.EnsureCounter(data.Metric); counter.WithLabels(data.Category).Inc(data.Increment); }
private Counter EnsureCounter(string metric) { if (!this.CounterMap.TryGetValue(metric, out var counter)) { counter = Metrics.CreateCounter(metric, $"{metric} Counter", new CounterConfiguration { LabelNames = new [] { "Service" } }); this.CounterMap.Add(metric, counter); }
Now we can find the metrics that our .NET application emitted.
Here is a simple counter graphed with Grafana.
Prometheus and Docker
Instead of running Prometheus as a local process, we can load it into Docker and run it. The directions on DockerHub tell you how you can use your own prometheus.yml configuration file.
Important: Since the .NET application is not running inside of the same Docker container as Prometheus, in the prometheus.yml file, you need to substitutelocalhost with host.docker.internal.
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. – job_name: “XP Voyager” # metrics_path defaults to ‘/metrics’ # scheme defaults to ‘http’. static_configs: – targets: [“host.docker.internal:9934”]
Notice that, in the volume argument, you need to use the absolute pathname of the prometheus.yml source file.
Grafana and Docker
To run Grafana as a Docker container:
docker run –name grafana -d -p 3000:3000 grafana/grafana
When you set up the Prometheus data source, remember to use http://host.docker.internal:9090 as the Prometheus URL if your Prometheus is also running inside of Docker.
In my past roles of CTO and Chief Architect, I have been involved in scores of code and architecture reviews. One of the services that I offer as part of my CTO-as-a-Service consultancy is to perform code architecture reviews of the apps that my clients are trying to go to market with. Some of the code has been developed by in-house staff. But, more often than not, I am called in to review code that has been developed by offshore development shops, the kind of shops that employ reams of “commodity” developers.
One of the reasons why I started CTO as a Service is because people used to come up to me and ask me how they turn their ideas into a product. Because of the time constraints of my full-time jobs, I would offer a little bit of advice in exchange for a beer. I would usually point these people to a number of development shops that I know, hoping that the development shop would be able to take the idea and turn it into a proper app. After that initial meeting, I did not involve myself any longer with the development of the app. I didn’t concern myself with the architecture that the development shop came up with, whether they were using a cloud provider, whether the code was clean, etc.
Startup founders who are non-technical usually have a little bit of money to develop the MVP of an application. Ideally, they would like to have a technical co-founder who would develop the app in exchange for equity, but there are a lot more ideas than there are CTOs with available time who will work solely for equity. So, the startup founder will search Upwork for a remote developer or will gamble with an off-shore development shop that has junior-level resources available for $25/hour. The startup founder usually has some wireframes and a written description of what the application is supposed to do. They throw it over the fence to the remote developers and wait with bated breath for the MVP to be delivered at some time in the future.
The problem that I constantly see is that there is nobody technical who is sitting on the side of the startup founder, representing the interests of the founder to the developers. There is nobody who is sketching out the architecture of the application. There is nobody making sure that the setup on AWS or Azure or Heroku will not incur massive cost overruns. There is nobody who is doing code reviews to make sure that the developers know what they are doing.
This issue is not confined to startup founders. There are well-established small companies who decide, for some reason or another, that they would like to create an app. For example, a venerable law firm that decides that they want to provide legal advice to their clients on a mobile app, or an old company that specializes in tutoring that decides that they want to offer an electronic version of their test-prep methodology. These companies often do not have anyone technical on their side to interface with the remote development shop.
A List of Code and Architecture Smells
You hopefully go to your doctor every year for a check-up. And, sometimes, you take your car into the mechanic for a yearly tune-up where the mechanic will see if the car is in good shape.
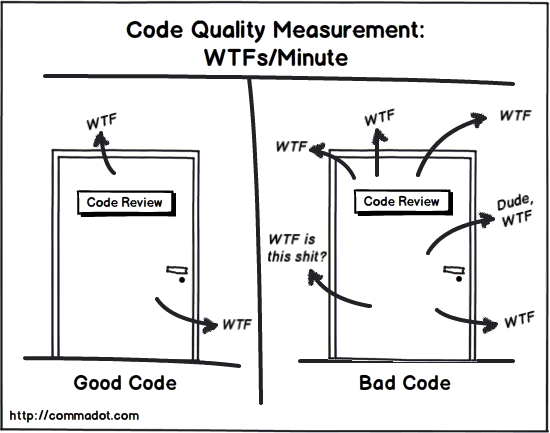
Similarly, you can take your app’s code to an experienced IT professional to see if it is well-designed and resistant to bugs. During this process, the IT professional will examine the code for certain “smells”.
“Smells are certain structures in the code that indicate a violation of fundamental design principles and negatively impact design quality.”
Someone with many years of experience developing systems (such as myself) can take a look at a code base or an architecture, and instinctively detect if there are funny smells around it.
The list of code and architecture smells comes from real-life reviews that I have done over the years. I will be adding to this list as I do more reviews for my clients. The list will never contain any mentions of my clients, my past employers, any specific products, or any development shops.
This list is designed for non-technical startup founders. As such, I will explain each smell and why it is bad for your app.
Code Smells
Too Many Hands in the Code
Someone’s coding style is like their fingerprint. When you give your app to a remote development shop to work on, you have no idea how many different people are going to write the code. Transitioning between different sets of developers takes time, and knowledge transfer can be spotty. Too many hands in the code might mean that the development shop has a lot of turnovers, it could mean that they are taking developers and transitioning them to higher-paying projects, or it could mean that they want to get your app done as quickly as possible and are attacking your app in a highly parallel fashion.
Lack of error checking and exception handling
There is nothing worse than having your app crash all of the time. If an app is unreliable, users will reticent to use it. Have you ever experienced the “spinner of death” in an application, where the app seems to be stuck? Nothing will drive users away faster than having their computers or phones lock up.
Every function call should be checked for null arguments, bad values, null return values, and other unexpected situations. Edge cases should be tested (ie: a negative number is used where a positive number is expected). A consistent exception-handling policy should be implemented.
Lack of Comments and Documentation
During the lifetime of your application, the source code will pass through many hands. Remote development shops can rotate different developers in and out of your code base. Although the lack of comments is not strictly a “code smell”, the lack of comments will result in a greater transition time for new developers to learn your application’s code.
At the very least, there should be comments for every module or class, and there should be comments for every public function and property.
Comments will not only assist developers in learning a codebase; it can also be used to generate system documentation. There are tools that will scan the source code and generate various types of documentation.
If your application has APIs that are meant to be used by other third-party developers, the API documentation can be automatically generated. The API documentation should adhere to the OpenAPI (aka Swagger) specification. Once the API documentation is in OpenAPI format, it can be presented in an easy-to-read format on a web page.
In addition to the comments in the code, all architectural decisions should ideally be memorialized. A Wiki, such as Confluence, is ideal for keeping records of design decisions. You should insist that your remote development shop delivers to you documentation around all major design decisions, and what alternatives were considered and discarded.
Copying of Code
Development companies who are under time pressure to implement apps can find themselves inserting copies of code into multiple places within the application. There can be multiple problems associated with copy-copying. First, if a bug is found in that piece of code, it needs to be fixed in multiple places. Second, the code can possibly “leak” responsibilities.
A good design will establish a firm “division of responsibilities” between different parts of the code. For example, there might be only one place in the code that is responsible for debiting and crediting a customer’s bank account. If you copy that code into different places within an app’s codebase, then the responsibility of debiting and credit a user’s account will have “leaked” into other parts of the code, making the app more difficult to maintain.
Breaking the Separation of Concerns
The code of an application should be composed of different layers. The typical layers include User Interface, Services, Repository/Persistence, Models, Controllers, Framework, Communications/Messaging, etc. Each layer has a specific responsibility. This rule is called “separation of concerns”.
A developer should not let responsibilities leak from one layer into another. I have seen code where a specific vendor’s user-interface library was referenced in the Persistence Layer. This not only creates a tight binding between the User Interface and the Persistence Layer, but it makes it more difficult to switch to another User Interface toolkit.
Another way of doing “separation of concerns” is to divide the application into various microservices. During an architecture review, we might want to consider the effort and the benefits of refactoring the codebase into microservices.
Improper Class Hierarchies
Well-designed code is akin to beautiful poetry. One thing that we look for in a code review is a sensible hierarchy of classes, and well as adherence to well-known object-oriented techniques. Common functionality might be put into a base class, which other classes inherit from.
A common base class for business objects is useful in order to implement common functionality such as validation, flagging if a model has been changed, shared properties (such as ids and audit information), etc.
Single Points of Failure
One of the most important things that we look for in an architecture evaluation is the single points of failure within an application. If a single service fails, or the connection to an important external service fails, will the entire application be hosed?
Your developers have no control over third-party systems that your application depends on. But you need to see if there are other third-party systems that can provide the same information that your application can use as a secondary source.
If your application is broken up into microservices, then there are various high-availability patterns that your developers can use in order to make your application more resilient to failures.
Key Person Risk
You want to avoid situations where a single developer on the remote development team is the only person who knows a key technology that your application is built upon. Likewise, any knowledge about “tricky” or “complex” parts of the codebase or the architecture should not lie in the hands of a single person. If it is, then you have “key person risk”. The consequences are that if this person leaves the company, you may not be able to fix errors or make improvements in the app.
It’s important to memorialize all important architectural decisions. A wiki such as Confluence is good for capturing all of the information about the architecture and the development process.
Resume-Oriented Development
Sometimes, the only reason why a developer chooses a certain technology is that they want to put that technology on their resume, no matter if that technology is not particularly right for the application. A choice of a nascent technology by a single developer could possibly result in key man risk, especially if that developer decides to leave the team.
In particular, I have seen many occurrences of a developer choosing the wrong database technology simply because the developer wants to gain experience with NoSQL databases at the expense of the client.
It is more difficult to back an application out of resume-oriented development. The best time to catch this is at the design stage. An experienced architect will be able to evaluate various choices for certain technology and identify if any of those technologies could present a key man risk.
Building when you should Buying
The decision to create your own software from scratch vs buying an existing product is always a difficult one.
When you incorporate someone else’s product into your architecture, you are beholden to the whims of that company to fix bugs and to release new features that you might need. You might also have the issue of “vendor lock-in”, where it is impossible to move away from a vendor’s product. On the positive side, you save money and effort by having your developers use something that is fully-baked.
During the design phase of a product, an experienced architect can recommend existing third-party products and frameworks that you can use within your application in order to get faster time-to-market without an excessive amount of risk.
One of the advantages of using a cloud platform like AWS or Azure is that there are new platforms coming out all the time, and these platforms are fully supported by cloud vendors. Almost every need that an app has an XXX-as-a-Service solution.
There is also a world of open source software that can be leveraged. There are certain rules to follow when choosing open source frameworks, but that is the topic of another article.
SDLC Smells
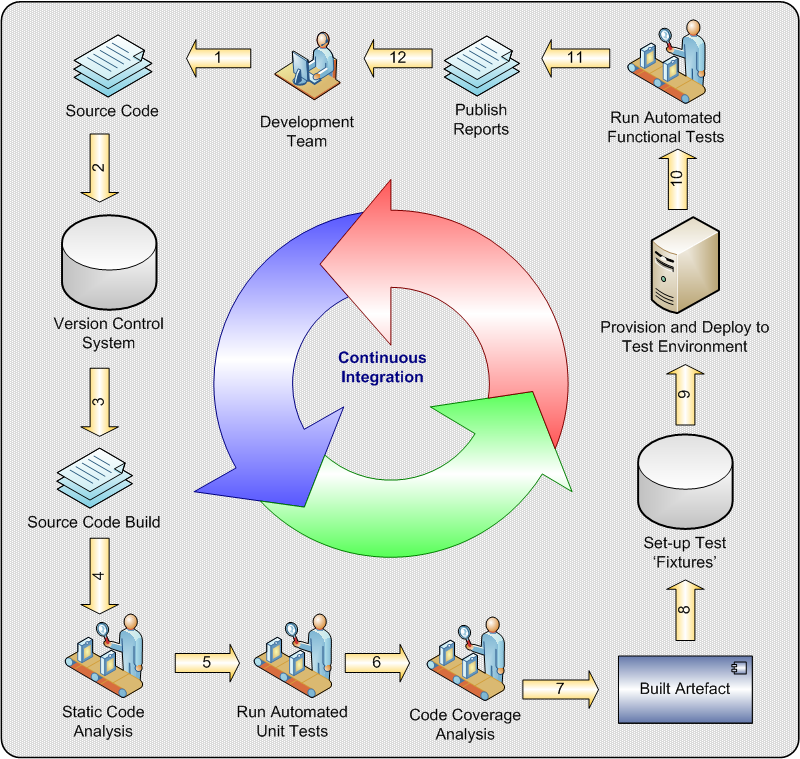
The Software Development Lifecycle (SDLC) describes how software is supposed to be developed. The chart below shows all of the steps that comprise a proper SDLC practice. In reality, many remote development shops do not follow each and every step, mainly out of concerns about cost and time.
Lack of Unit Tests and Integration Tests
Developers are changing code all of the time, fixing bugs and adding new features. As they are creating new capabilities for your app, you have to feel comfortable that the existing code will continue to work.
This is where unit testing and integration testing come in. A unit test will test certain functionality in a piece of code. Ideally, every function within a module (or class) should have an associated unit test. Ideally, every code path in the application should be tested by a unit test suite. The percentage of all code paths that have unit tests is called “code coverage”. Ideally, an application should have 100% code coverage, but unless your project is developed using Test Driven Development (TDD), that percentage often falls short of 100%.
It’s extremely important to not only test the “happy path”, but to test that the code will not break when it encounters bad data. This means that you need to write unit tests that pass bad data into functions. You also need to be able to cause the code to generate an exception and write tests to make sure that the code is generating these exceptions when encountering error conditions.
Of course, you need to make sure that the code actually has error checking and exception handling, which is a huge code small if it doesn’t.
An integration test will test the interaction between multiple modules. For example, a function that is supposed to debit a bank account should result in a decrease in the customer’s “available balance” column in the database. So, not only do you need to make sure that the “DebitCustomer()” function is tested, but you need to read the database to make sure that the available amount has changed.
A regression test will compare the results of two separate runs of the test suite to make sure that the values produced by running a test suite are not different (or different within a certain tolerance) than the results of the previous run of the test suite. In addition to comparing actual values that are produced by the app, we can also test the performance time of various parts of the app. We want to make sure that a new version of the code is not noticeably slower than the previous version. If the app starts to crawl, then users might get frustrated and might abandon the app.
There are tests that can be written to test what happens to your system when it is under heavy load, which is what will happen when Oprah Winfrey mentions your app in an interview. These are called soak tests and stress tests.
No Continuous Integration
Continuous Integration is important in the Software Development Life Cycle. When a developer checks the code into a source code repository (like Github or BitBucket), all of the unit tests are automatically run. A failing unit or integration test will identify problems immediately before those problems seep deep into the app and find their way into the production version of the app.
You might have several developers working on your app. For example, in many development shops, you would have one developer working on the backend (the database and the server), you would have one developer working on the front-end (maybe a website), you might have one developer working on the iPhone version of the app, and finally, you may have another developer working on the Android version.
All of these developers would have the code “checked out” from the source code repository, maybe in a separate branch. When it comes time to release a new version of the app, all of the developers would have to merge their code back into the main codebase. The longer a developer has a branch checked out, the more prone the app is to errors when the developers check in their code. If things don’t go smoothly, as they often don’t, it can result in what is known as “integration hell”. This costs you time and money.
Continuous Integration should be performed frequently, at least once per day, if not more. The mantra is “Check in early, check in often”.
Some remote development shops do not use continuous integration. Why is this? Writing unit tests and integration tests are tedious and costly. Development shops make money on churning out as many apps as possible in a given timeframe. When you do not have testing and continuous integration set up, you incur “technical debt”. And, sadly, tech debt always comes back to bite you.
Data Access Smells
No Caching
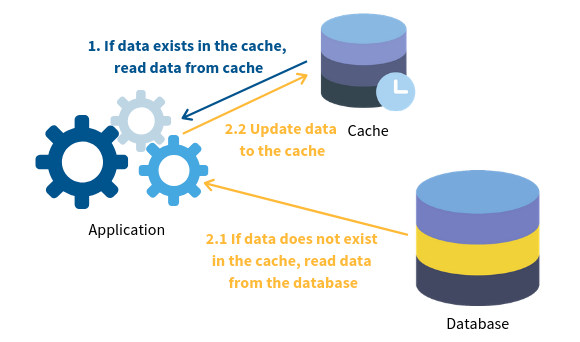
In order to access and store your app’s data, you have to make a call into a database. However, database calls are relatively expensive. There is the time it takes for the data to be transferred over the network. Certain database operations can take a relatively long time to execute. And there can be “deadlocks” that occur when multiple callers try to access the same data.
One of the common architectural smells is the absence of caching. There can be no better performance-killer than hammering a database with a lot of operations, especially the operation of putting data into the database.
Good application design will employ “caching”. With caching, data is stored in memory within the application. The cache is checked for the data your app needs, and only if that data is not found will the database be accessed.
I can’t tell you how many code reviews I have done where I have detected an absence of caching. And the introduction of even a small in-memory cache has resulted in dramatic improvements in the performance of certain parts of an app.
Multiple Avenues To Update a Database
When we use caching, it’s important to keep the cache in sync with the database. Imagine if the cache contains a value that is the customer’s available balance, and some other app goes directly to the database and updates available balance in the database. The cache will not know about this update, and as a consequence, the original app might have a “stale” value for the customer’s balance.
During an architecture review, it is important to look for all code, services, and applications that can change a database, and if possible, we need to force all database access to go through a single gateway. This way, we can ensure that any caches that the app maintains will be totally in sync with the values in the database.
If this is impossible to do, then there should be a mechanism where database-update events are broadcast to various services in the app, so that these services know that they need to refresh part or all of their cache.
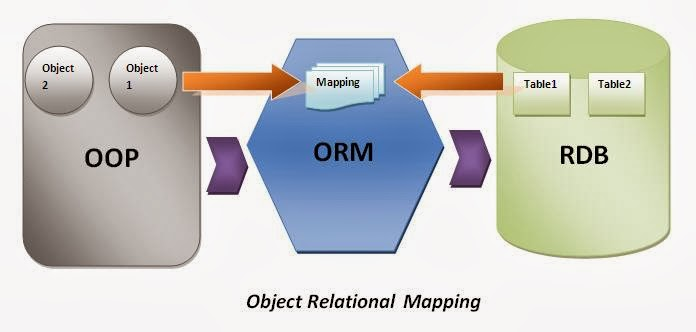
Bad Use of ORMs
An Object Relational Mapping framework (ORM for short), is a way that developers can translate between high-level objects and a relational database. If a developer writes the app in an object-oriented language like JavaScript, C#, or Java, it can be tedious to deconstruct an object and store each field in appropriate tables in a database. An ORM will translate that object into SQL calls to the database.
The problem sometimes with ORMs is that the SQL code that is generated can be slow. This has been a long-running complaint with ORMs.
Careful examination should be made of the database interaction that is controlled by the ORM. There are various tools for databases like SQL Server that will monitor the calls to the database and may suggest improvements. You should consider moving frequently-used ORM-generated calls into SQL stored procedures, and calling those stored procedures directly.
Data Type Mismatches Between Database and Code
There are applications who store certain data as a non-optimal data type within the database. For example, dates and currency values should not be stored as text fields. This makes it easy to store incorrectly-formatted values inside of the database. Storing dates and numbers as text strings make it more difficult to do arithmetic on the values. The developer first has to convert the text field into the correct data type, hope that the conversion succeeds, then perform the arithmetic on the new value, then convert the result back into a text field. These needless conversions are tedious and error-prone.
Special care also needs to be taken to make sure that the code will handle “nullable columns” correctly. These are values that are optional within the database. The code should never assume that a nullable column contains a valid value.
Out-of-Sync Views
If there are multiple people working on the same case, and there is a change that one person makes, the other person will not see that change until a fresh call to the database is made. That can lead to situations where there is stale data on somebody’s screen.
Many web applications use real-time messaging to notify the user interface that something in the model has changed. For ASP.NET MVC, there are frameworks like SignalR that will help implement real-time notifications between modules of an application.
Security Smells
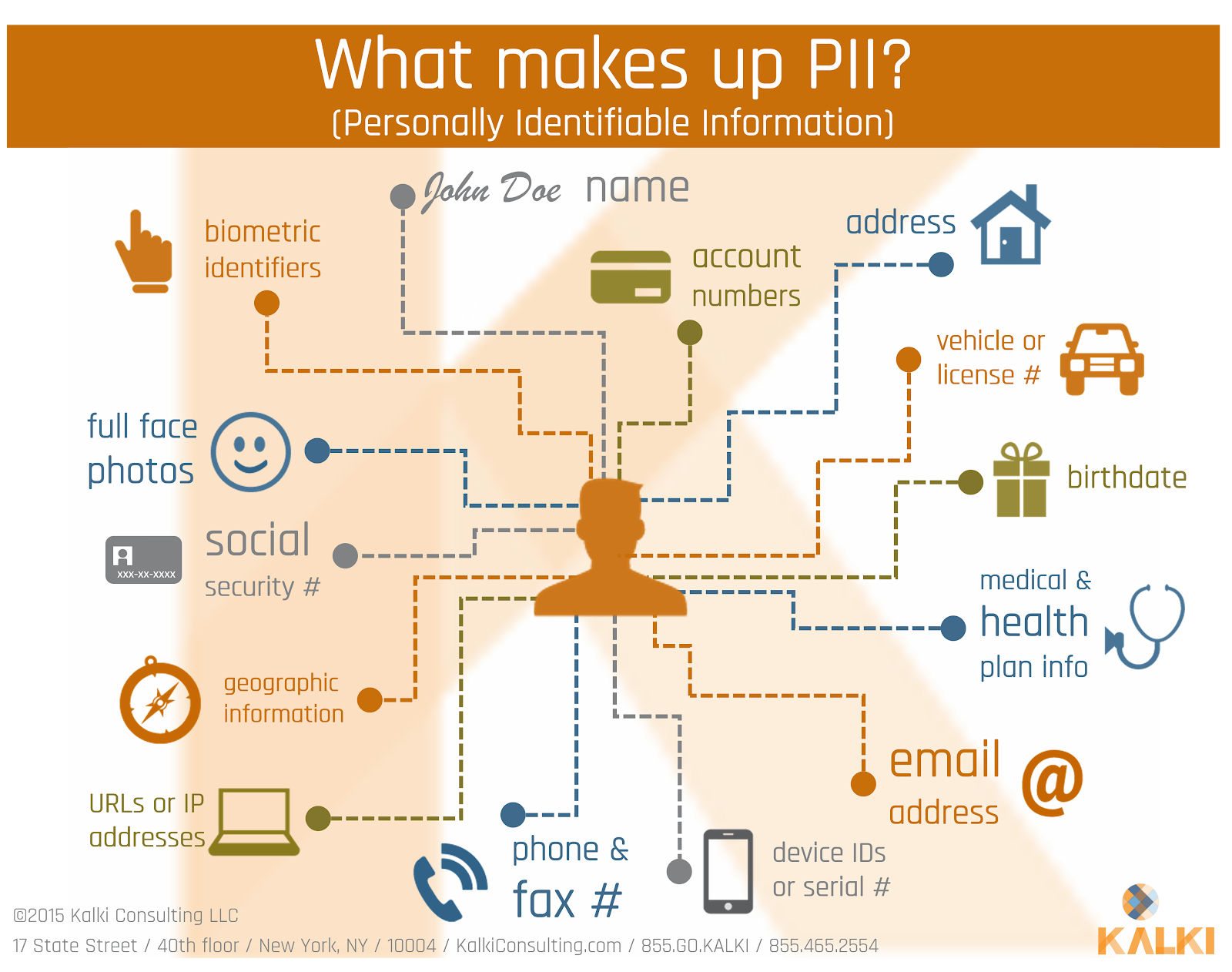
Storing PII in Plaintext
Personal Identifiable Information (PII) should never be stored in plaintext. I have seen cases where configuration files have sensitive password information that can easily be compromised by a hacker. A full scan of the codebase should be made to ensure that no passwords are stored in plaintext anywhere.
Test data should never include any PII. I have seen cases where a test database contains social security numbers and password in plaintext form.
Passwords and PII should never be stored in a source code repository like Github. It is common to stored passwords in the .env file in Node js applications. Be sure that the .env file is never stored in a repo.
If you are in Europe, all apps have to be GDPR compliant. If it is not, it can mean big fines and possible shutting down of the app. So take PII very seriously.
No Authentication in the public API
Exposing an API layer for your app is a great way of encouraging third-party developers to create new extensions for your app, thereby making your app even more powerful. But, you do not want to make your app the “Wild West”, with unfettered access to your platform.
Make sure that APIs that your app exposes have proper authentication. You may want to make some APIs truly free and public, but anything that writes data to your database or changes the state of your application should have proper authentication around it.
Performance Smells
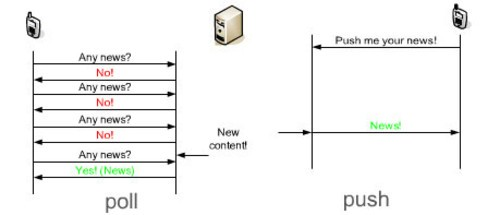
Frequent Polling of Services
An application can have a connection to various internal and external services that contain data that is critical to the app. For example, your real-estate app might be connected to an external Multiple Listing Service (MLS) server that contains information about new homes that came on the market. What your application may do is to connect to the MLS service every few minutes, download data, see if any of that data changed since the last time the app connected, and notify the user that something changes.
If there are multiple internal and external services that our app has to connect to and “poll” for changes, then our application can take a performance hit, especially if there are a lot of services to poll.
A much better way of getting data updates is to let the external services “push” data to your application. Your app basically subscribes to updates, sits back, and lets all of the services push events when something interesting happens.
Applications should attempt to migrate from the “pull” model to a more modern “push” model of updates. This is usually accomplished by using webhooks, which are HTTP-based POST calls to a URL when an interesting event occurs.
No Provision for Scaling
My favorite thing to say to startup founders is: “What happens if Oprah mentions your product? What happens if you have 10,000 people hitting your app servers at the same time? Can your app and infrastructure handle the load, or will your app crash and burn?”
A good architecture will be able to let an app scale up seamlessly. Cloud providers like AWS and Microsoft Azure and Google Cloud Platform provides services that will automatically let you scale your application upwards when you need it, and downwards during slow times.
An architecture review, along with proper soak and stress testing, will make a startup founder more comfortable that their application will be able to handle the “Oprah Moment”.
The list of various smells that this article contains is only a small portion of the smells and anti-patterns that a trained senior technologist will look for when evaluating the architecture and codebase of applications. CTO as a Service has over 30 years of writing systems, leading development teams, and doing architecture reviews. Please consider CTO as a Service to give your applications a health-check from time to time.